
The data comes from a Research Letter published in JAMA Internal Medicine, where the researchers compared an algorithm's diagnostic acumen with the medical staff's decisions. The model [1] would calculate a sepsis score every 20 minutes based on the live medical record being created in the Emergency Department. The primary outcome was the time required for the algorithm to identify sepsis; the control, the identification of sepsis by the clinical staff as defined as the ordering of bacterial cultures or antibiotics. Since the ongoing sepsis scores were not shared with the clinicians, the control was “blind.”
Eight hundred thousand encounters across a nine-hospital system were studied; 28% were from the largest, presumably the most experienced of the nine.
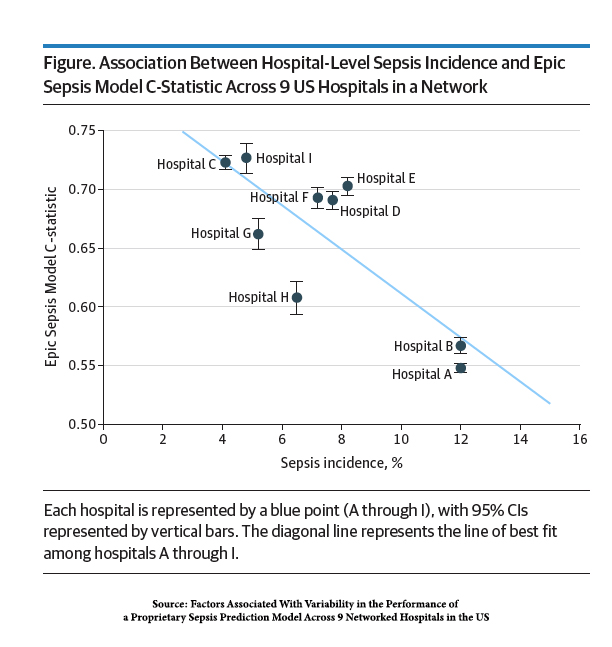 Sepsis ranged from 4.8 to 12% across the hospitals in the system.
Sepsis ranged from 4.8 to 12% across the hospitals in the system.- The ability of the algorithm to identify sepsis in a timely manner ranged from 0.55 (the coin toss is 0.50) to 0.73 based on a C-statistic [2]. A value of greater than 0.7 is considered “good.”
- The ability to identify the septic patient from the not septic was statistically significant in hospitals with fewer cases of sepsis, and fewer co-morbidities and cancer, where symptoms can mimic the early findings of sepsis.
In other words, the algorithm did quite poorly in large hospitals with many patients with sepsis; in hospitals where sepsis is not seen as much, it fared better – “good” not great.
The researchers point to larger hospitals having “other clinical disorders [that] could mimic sepsis” and the perennial explanation that their documentation may be “unique.” The higher predictive value in hospitals with fewer cases made it “most useful at lower-acuity hospitals.”
This does remind me of a story by Calvin Trilling describing how he would often take visiting relatives to New York’s Chinatown to play Tic-Tac-Toe with a chicken. More often than not, the visiting relative lost to the chicken and would often comment concerning their loss that “the chicken got to go first," or that "the chicken played every day.”
The researchers end as optimistically as possible, suggesting that the next iteration of the sepsis algorithm would be based on data from individual hospitals rather than an aggregate. That might prove to be a two-edged sword; the data collected will undoubtedly be more reflective of local clinical presentation. However, with fewer cases, the strength of the underlying relationships may be weak or uncertain.
In the meantime, we continue to buy the Silicon Valley snake oil of healthcare A.I., solving many challenging problems; it is just a little over the horizon. We also seem intent on believing the smoke and mirrors of the corporations embracing these tools, which to this point, have done more to enrich their bottom line than our lives.
[1] The algorithm is the Epic Sepsis Model employed by many health systems. You can find my previous writing on this algorithm here and here.
[2] The C-statistic, in this instance, measures the probability that any random patient with sepsis will be identified compared to any random patient without sepsis.
Source: Factors Associated With Variability in the Performance of a Proprietary Sepsis Prediction Model Across 9 Networked Hospitals in the U.S. JAMA Internal Medicine DOI: 10.1001/jamainternmed.2022.7182

Chuck Dinerstein, MD, MBA
Director of Medicine
Dr. Charles Dinerstein, M.D., MBA, FACS is Director of Medicine at the American Council on Science and Health. He has over 25 years of experience as a vascular surgeon.


